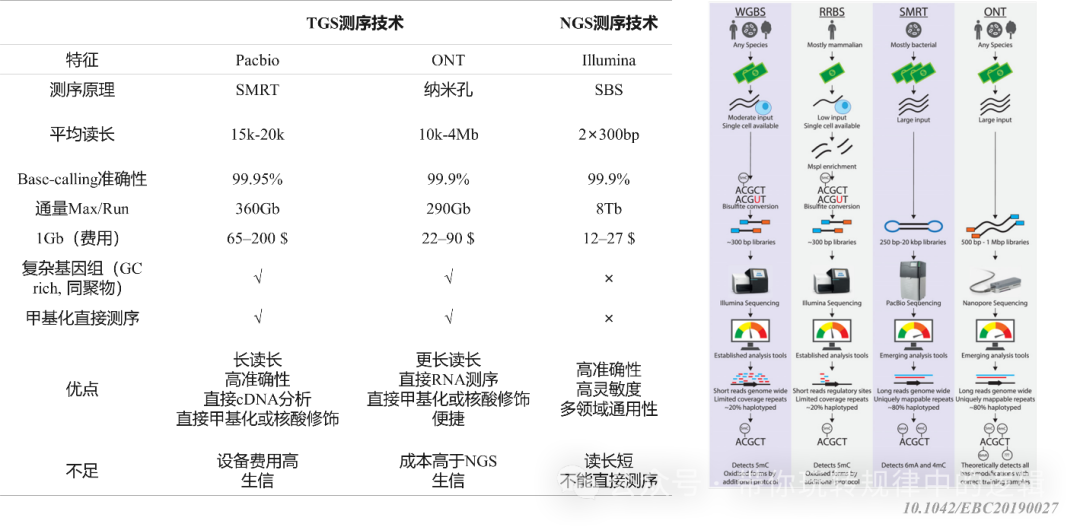
如果把测序的通量比作工作效率。其效率则由生产三要素决定,即生产力、生产资料、生产工具则是必不可少。一代测序技术可以理解为奴隶社会的刀耕火种时期,即使昼夜不停,也只能通过加强工作时间提升生产率,因为其生产力、生产资料、生产工具得不到提升。二代测序技术可以理解为工业革命时期,提升了生产资料和生产工具,自然工作效率也得以由量变转化为质变。三代测序技术可以理解为信息化革命时代,尽管生产资料和生产工具很先进,但受限于如成本、应用场景和准确度等方面因素得不到广泛的发挥而仅占据市场的一席之地。 测序的本质是将体内的核酸拿到体外,类似拼图的方式绘制一幅完整且准确的核酸图谱。
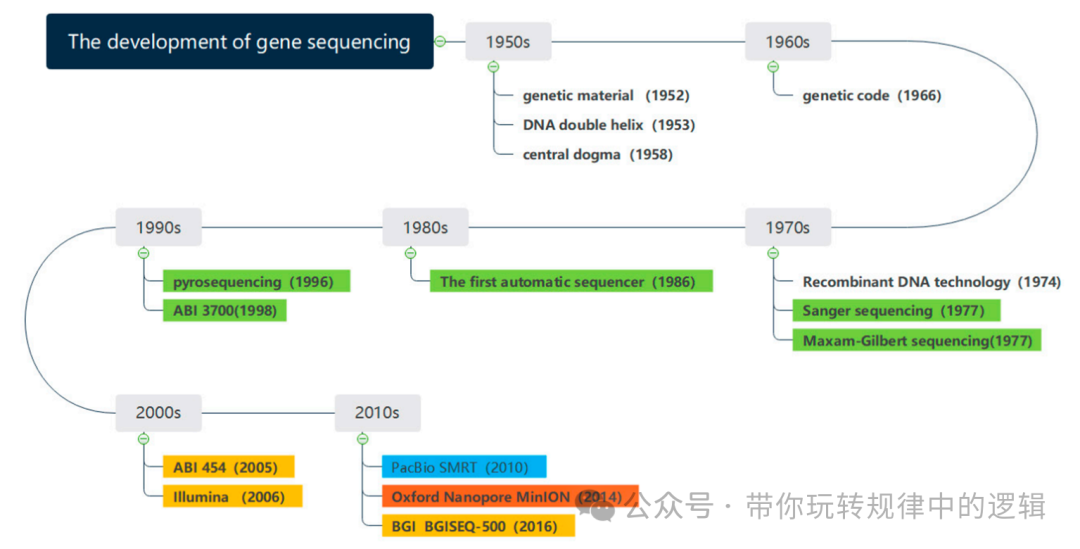
测序技术从1977年ABI公司的Sanger测序技术问世,到2014年Oxford Nannopore公司推出长度长的37年时间内,2005年Roche推出的454测序相对Sanger测序晚了28年,但不久的2008年Pacific Biosystem推出单分子测序,仅仅比454晚了3年。可见技术的更新和发展是愈加快速的。 然而,无论一代测序、二代测序还是三代测序,是需要解决实际问题的,如成本、通量、准确度、长度、测序背景等问题。下面就以发展的角度讲一讲测序的那些事儿。 1.1 技术原理与平台对比典型的测序技术如Sanger测序、边合成边测序(SBS)、单分子测序(SMART)、纳米孔测序。有人把第一代测序技术,如Sanger测序比喻成老式打印机,需要逐个敲打记录核酸信息;把二代测序技术,如illumina测序比喻为复印机,能够实现同时扫描千万个段片段;把三代测序如PB和ONT测序比喻为安装了高清摄像头的无人机,实时检测和传输全景信息。 通俗的理解,其实就是利用DNA的特点和测序的原理紧密结合,人为的构建符合测序仪识别的DNA分子。有点变相的PCR技术,只是PCR的结果需要凝胶成像看了大小后再通过Sanger测序显现DNA序列信息,而测序是同时采集了DNA的序列碱基信息,转换成计算机语言。
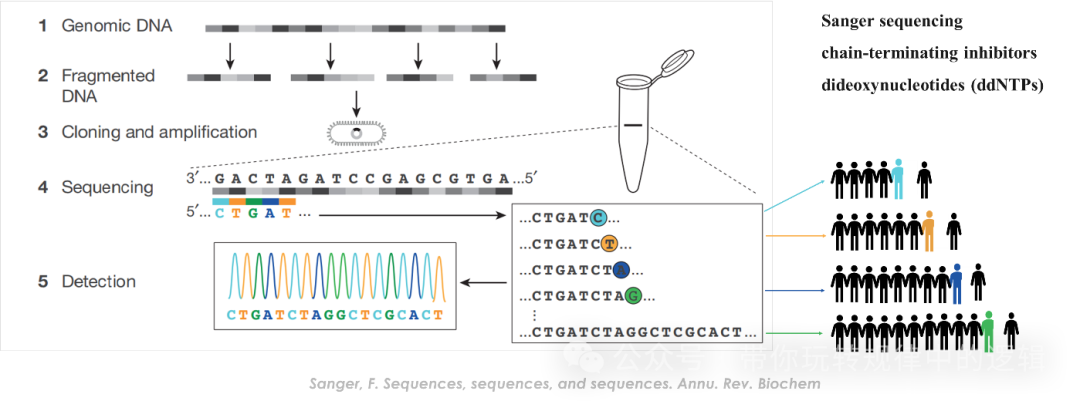
一、一代Sanger测序 Sanger测序可以类比为PCR技术,即通过通用引物互补到模板链上,利用聚合酶的合成未知序列信息,再把信息转化成碱基的荧光信号。对于Sanger测序的样本多为质粒(易于储存、运输),也有PCR产物或者菌液(也是通过纯化或提取的方式处理后再进行测序环节的操作)。 Sanger测序又称双脱氧终止法测序,利用了ddNTP混合在dNTP中。其技术原理通俗的理解为小孩子过家家手牵手的小游戏,把测序需要的dNTP比喻为有2只完整手臂的小孩,把ddNTP比喻为只有1只手臂的小孩。测序开始时,在聚合酶的作用下遵循5’到3’的方向进行碱基互补配对,此时如果是合成原料dNTP,则有2只手,可以继续牵着下一个碱基往下合成;但若遇到了ddNTP,则只有1只手,本轮反应则结束,终止的地方通过跑胶呈现A、T、G、C的不同组合分布,把序列拼接一起,即获得一条完整的核酸序列。
步入千禧年后,随着人类基因组计划告一段落,测序技术的普遍使用和技术的大力推广,使得测序成本持续下降,尤其是2014年illumina广泛入驻中国市场,将Sanger测序的成本从几十元一个反应降到几块钱一个反应。这也标志着盛行20多年的Sanger测序时代迎来英雄暮年的市场—专注擅长的领域发光发热。
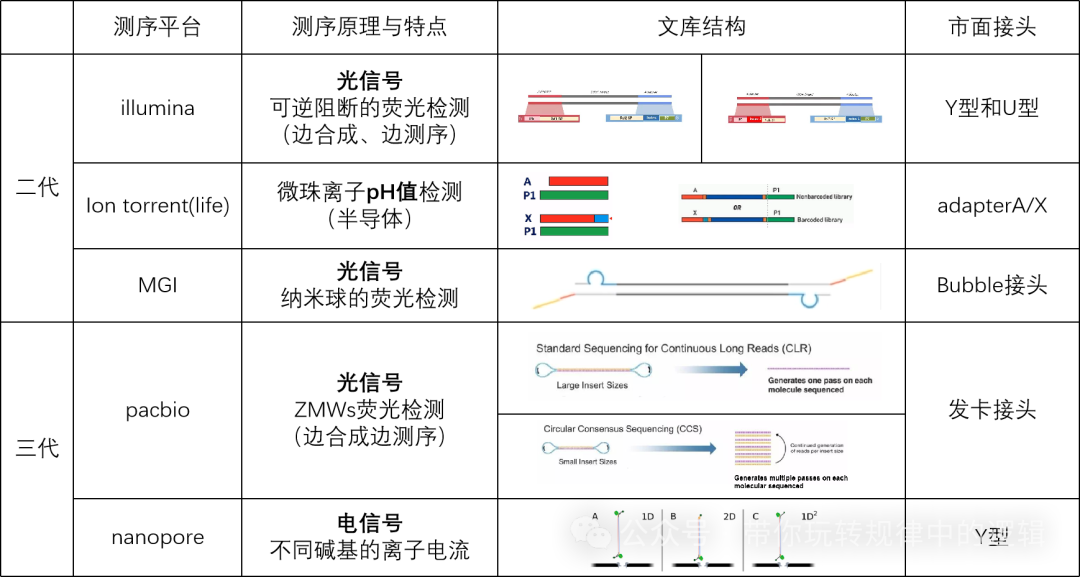
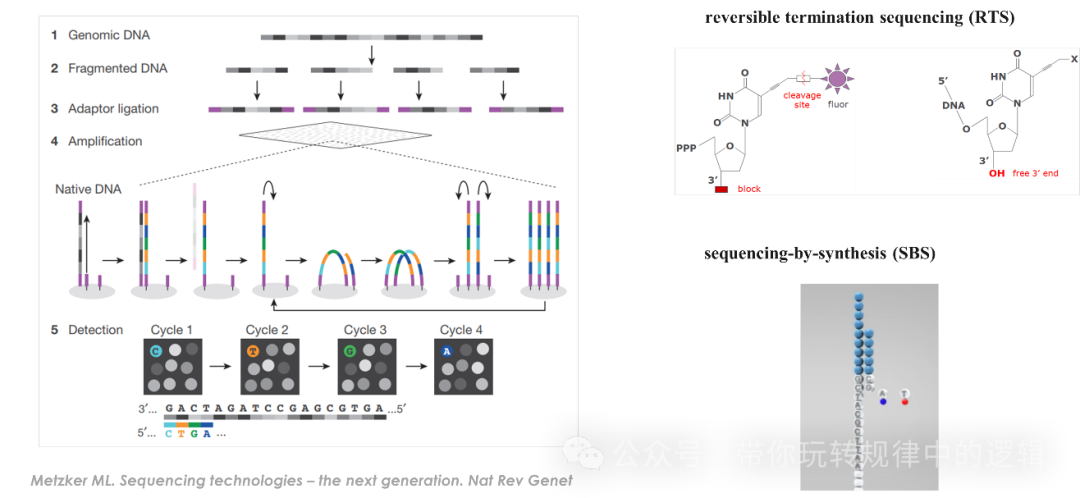
二、二代测序技术 二代测序典型技术以边合成边测序为主,如illumina。当然也有ABI的Ion torrent平台、华大智造MGI的DNBSEQ和MGISEQ系列。 以illumina为例,Illumina的测序流程分为4个环节,分别为文库制备、簇生成、测序、数据分析。这里简单说下文库制备的一些信息,以便于理解为什么要制备文库。
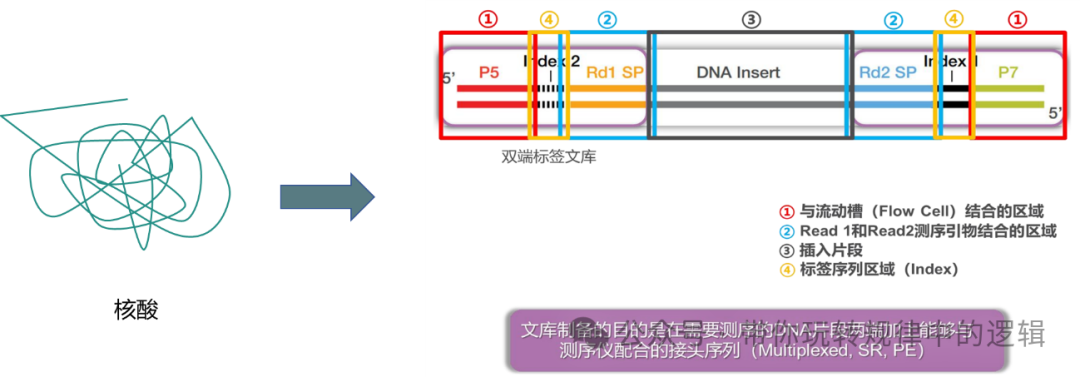
文库制备,简单理解即搭积木,如下图所示,要将左边一团核酸以某种或多种可实现的技术方式搭建成右边的文库结构。右图中除了一定长度的DNA需要人为用不同方式处理,其它序列都是已知的。
一般满足illumina测序的DNA长度在600bp以内,这根据测序的目的选择。之所以需要控制DNA的长度,这里和测序的背景信号干扰有关。简单说明即整个测序反应是在一张芯片上进行的,里面有千万条分子,当加入含有荧光基团的碱基时,这些荧光基团多少也会留在整个反应中,随着测序时间的延长,这些荧光基团就会干扰正确的荧光采集,使得测序的准确度下降。因此为控制测序的准确性,对DNA的长度会有限制。比如Pair End 150(双端各150bp测序)的文库DNA片段的长度集中在200-300bp之间。而已知序列则需要通过一定的方式连接到DNA的两端,这里就不得不选择连接酶进行dsDNA的连接。最终形成上图右边的结构即可。
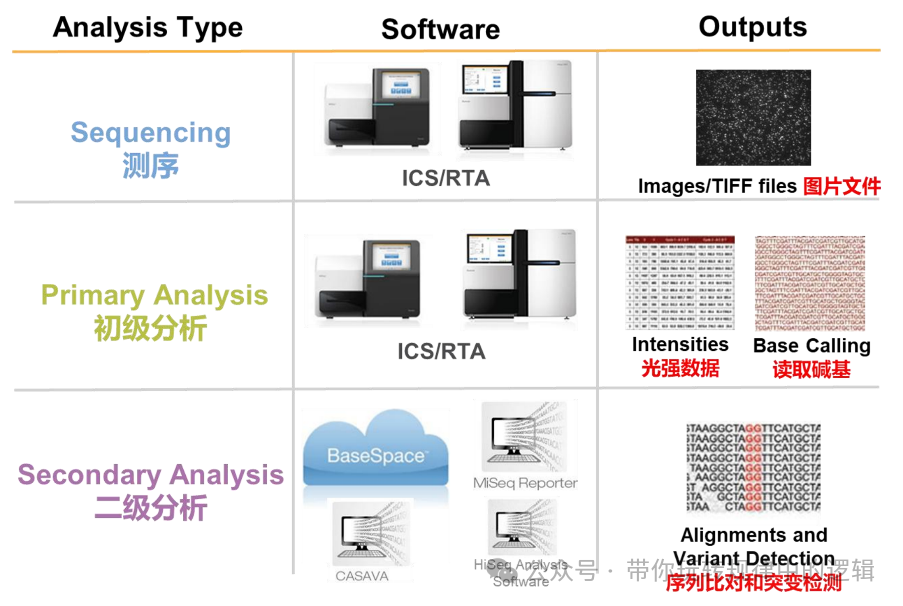
簇生成,可以理解为DNA分子数量不够测序时的要求,那么就需要通过“扩增”富集相同的分子千千万,确保任何一条DNA分子都能够被测到。这里就引入了桥式PCR扩增(想要了解原理的可以检索),利用文库的已知序列,把DNA分子的正义链和反义链都分别进行富集。待满足簇密度后,才能保证测序的数据量。 测序的时候,引入了可逆末端终止法的技术,即测序的dNTP的 5’带有荧光基团(测序仪器采集的信号),3’被封闭了。这样的好处是只有互补配对的碱基才能结合到模板链上释放荧光被采集,而释放了荧光信号后3’的封闭则暴露为-OH,方便下一个配对的碱基结合后形成磷酸二酯键,依次形成完整的DNA链。 测序的结果遵循以下步骤进行分析。
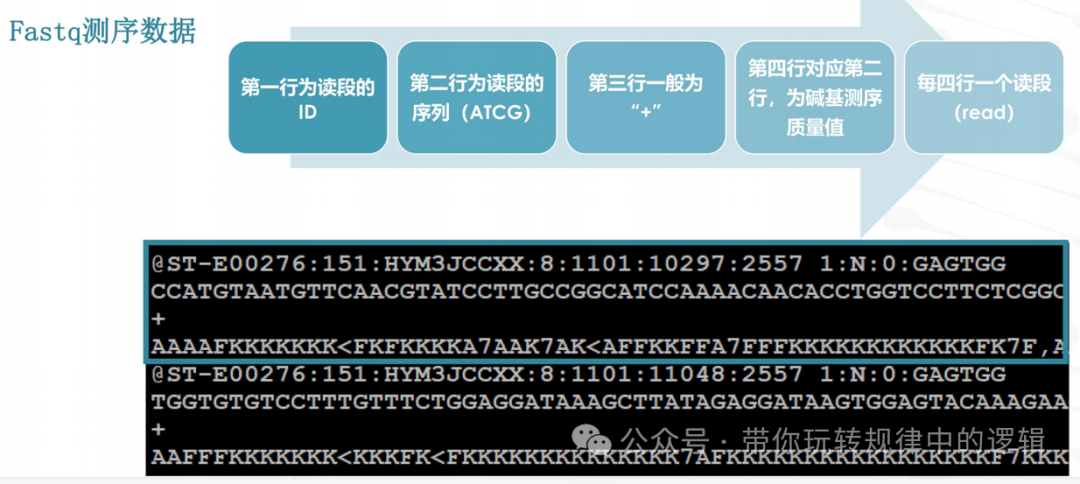
测序的文件为Fastq文件,数据信息如下。
类似的Ion Torrent和MGI的测序除了原理不同,在文库制备上有异曲同工之处。感兴趣的可以检索测序原理,本文不再赘述。
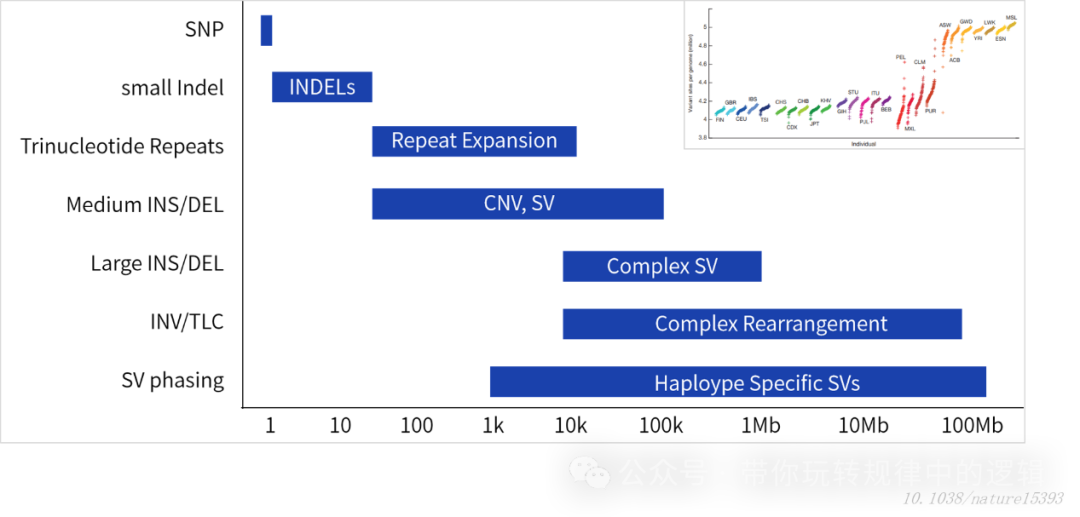
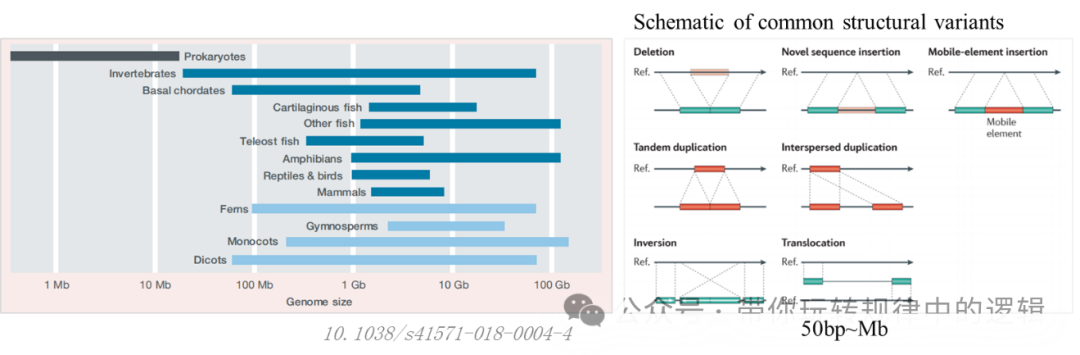
尽管二代测序因其通量和准确度备受瞩目,也随着成本的降低和国产化仪器的替代,下沉市场的同时也在走出国门。但也存在技术的瑕疵。简单罗列如下: I. 受限的重复区域:一些大基因群的物种含有高度重复区域,二代测序在拼接上满足不了对其准确度的要求。又如人类基因组中约50%是重复序列,染色体端粒的“TTAGGG”重复上千次。二代测序的短读长因对连续序列的读取准确度低的问题,导至基因组组装时出现大量缺口。 II. 结构变异盲区:许多疾病相关的基因变异并非单个碱基突变,而是大片段DNA的插入、缺失或倒位(如BRCA1基因的致病变异)。或者在空间位置上的结构变异,使得拼接的信息丢失关联性或者拼接位置错误等,误导验证性结果。 III. 丢失表观修饰:DNA甲基化、RNA甲基化等化学修饰携带重要调控信息,但传统测序需要经重硫酸盐或甲基化酶处理,亦或者通过成本很高的WGBS或改良的RRBS技术,才能结合着二代测序获取修饰信息。
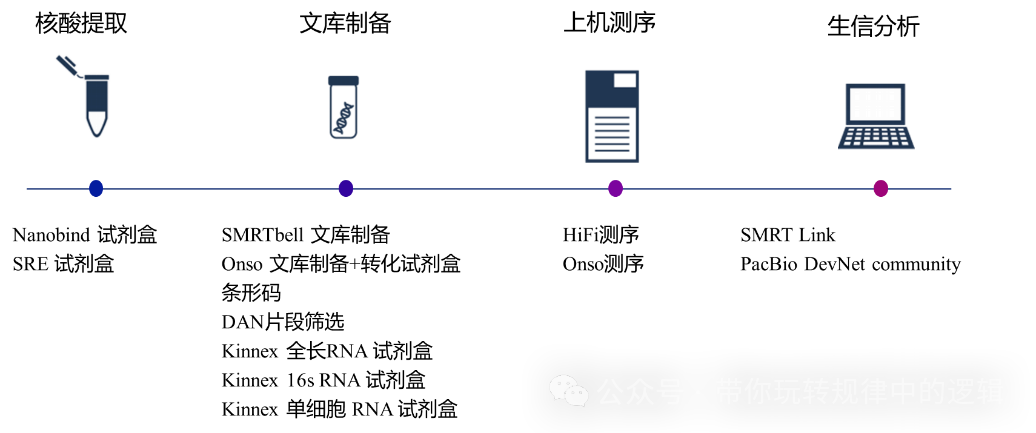
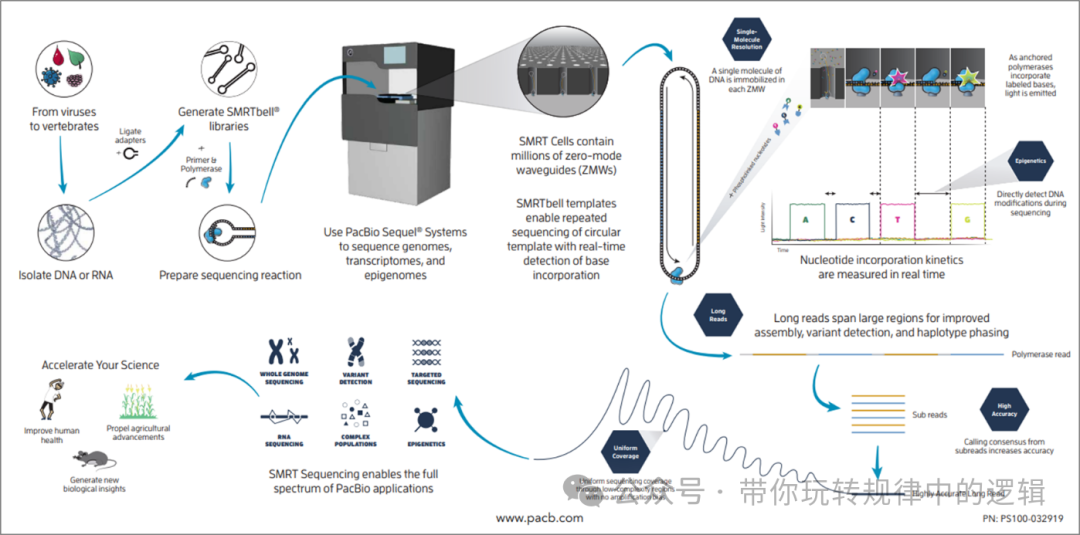
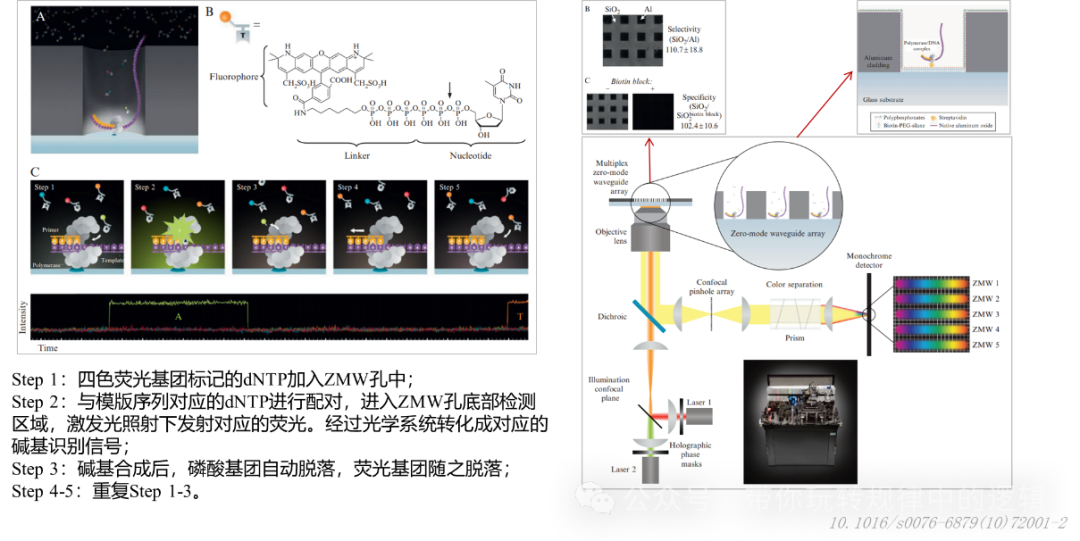
三、PacBio单分子实时测序技术 通常地,人们把Pacbio测序称之为三代测序,其全称为Pacific Biosciences(简称PacBio)的SMRT(Single Molecule Real-Time,单分子实时)技术。其全流程也是核酸提取-文库制备-测序和实时数据分析。
其核心技术包含2个,1个是四色荧光基团的dNTP,相对于二代测序的荧光基团的dNTP,除了多了linker减少空间效应,还降低了信号干扰;另1个是由链霉亲和素锚定DNA聚合酶在100nm的零模波导孔(ZMW),当聚合酶识别文库分子进行互补配对测序时,荧光标记的核苷酸会发出瞬时闪光,被底部探测器捕捉记录。
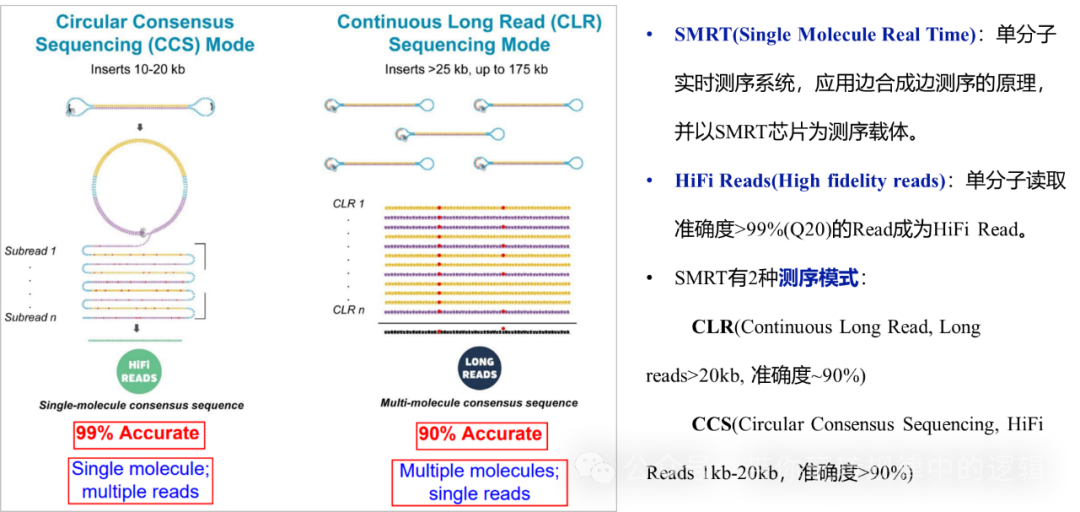
Pacbio测序有2种模式CCS和CLR。简单理解CCS模式是把一个分子持续测,测到终止测序为止,这样就能tongg 反复一个分子进行序列纠错。CLRze 为一个分子只测一遍,但是对千万条分子都测序。
优势: 环形一致性测序(CCS):通过将线性DNA首尾连接成环状分子,聚合酶可以反复读取同一片段(通常10-20次),将原始准确率从87%提升至99.9%。 HiFi reads:高保真模式下的超长读长(10-25kb),特别适合解析高度重复的基因组区域。 表观修饰检测:通过加入甲基化特定的dNTP监测聚合酶的合成速度变化,直接识别甲基化(如5mC)等化学修饰。 平台对比:
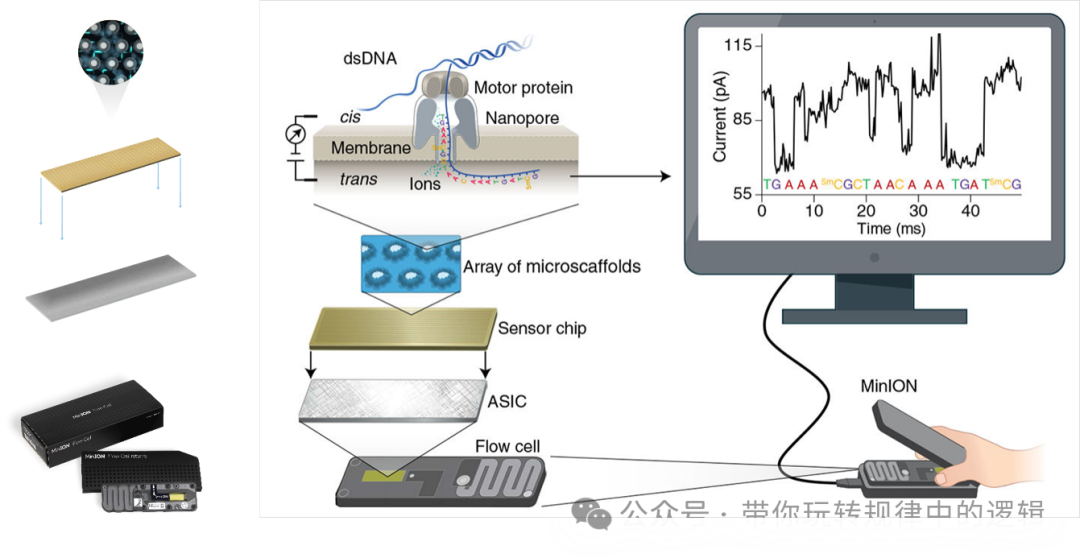
Sequel IIe:主流机型,单张芯片可产生100Gb数据,平均读长10-25kb。 Vega:2024年推出的桌面式测序仪器,数据质量提升至Q30>90%的同时,也确保直接测序甲基化核酸。 四、Nanopore技术:穿越纳米孔的电流密码 Oxford Nanopore Technologies(ONT)的技术原理——让单链DNA像线绳穿过针眼一样通过生物纳米孔。当不同碱基通过孔道时,会引起特征性的电流变化,通过解码这些电信号即可识别序列。这种“直接电信号读取”的模式,实现了从DNA到数据的零距离转换。 有人将纳米孔测序称之为四代测序,也有的称之为3.5代测序,但大体还是三代测序的长读长没变。
从2014年商业化的Flongle后,从孔蛋白数量、芯片升级、通量提升、测序准确度提升、数据流量等方面都在加速迭代。因其早期定位微生物和病原测序,故在新冠期间其应用场景的优势更加凸显:随时随地测序、端口可接Type-C的便捷性,为传感染领域激增纳米孔测序的应用得到更大的提升。
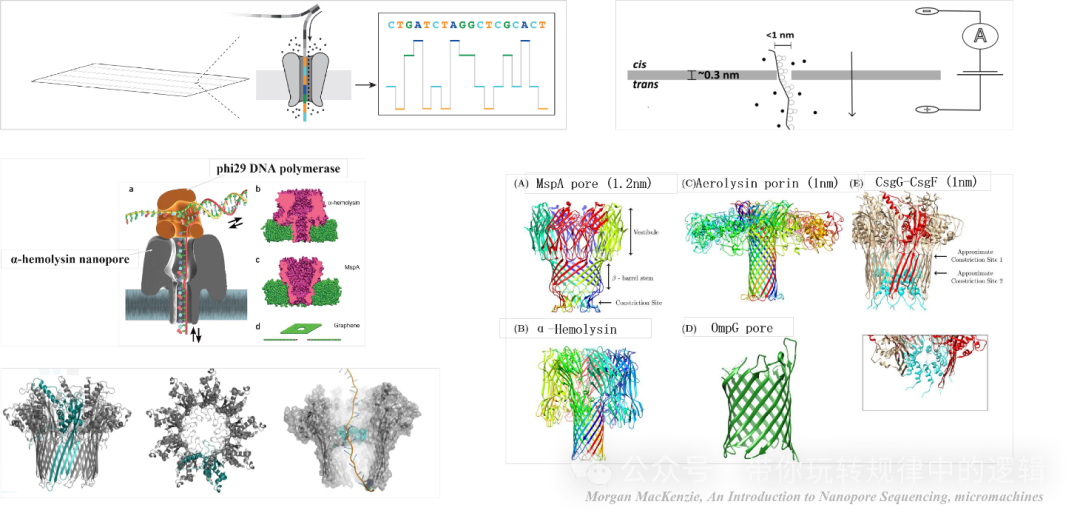
优势: 超长读长纪录保持者:已实现单个分子超过4Mb(400万个碱基)的连续读取。 实时测序:数据生成与信号检测同步进行,最快5分钟内获得首批序列。 直接RNA测序:无需反转录,直接读取RNA分子及其修饰。 技术核心: 纳米孔结构:使用工程化蛋白孔(如R10.4版本),孔径仅1.5nm,确保单个DNA链通过。 马达蛋白:一种解旋酶(如phi29 DNA聚合酶)控制DNA通过速度(约450碱基/秒),类似于控速器。 信号解码:机器学习模型将电流波动转化为碱基序列,最新算法准确率已突破99%。
硬件生态: MinION:U盘大小的便携设备,适合野外或床边检测,单次运行成本约$1000。 PromethION48:工业级平台,48张芯片并行,理论通量可达30Tb(相当于100个人类基因组)。 五、二代与三代测序的较量
谁更适合你的研究? 选择PacBio当... ²需要99.9%的超高准确率(如临床诊断); ²研究复杂基因组(植物多倍体、癌症结构变异); ²需要同时检测DNA甲基化; 选择Nanopore当... ²追求超长读长(解析端粒、着丝粒等区域); ²需要实时监测(疫情暴发时的现场测序); ²预算有限但需要灵活扩展(从$1000到百万级项目); 六、技术瓶颈与突破方向 尽管二代和三代测序的优势明显,但对于三代测序的两大平台仍面临关键挑战: I. PacBio的窘境 通量成本困境:即使Revio平台将成本降至$1,000/人基因组,仍是Nanopore的3-5倍。 GC偏好性:高GC含量区域可能导至聚合酶“卡顿”,读长分布不均。 样本质量敏感:长片段DNA制备难度大,机械打断易损伤完整性。 II. Nanopore的技术难关 同聚物错误:连续相同碱基(如AAAAA)的电流信号难以区分,错误率偏高。 孔道稳定性:部分孔道在运输和仪器测序运行中失效,导至数据损失。 计算资源黑洞:原始信号分析需要强大GPU支持,小型实验室难以负担。 III. 创新解决方案 PacBio:开发抗损伤酶(如升级HiFi酶或者使用watchmaker的高保真酶),提升复杂样本处理能力。 Nanopore:推出R10.4.1芯片,将同聚物准确率提升至99%。 共性突破:结合AI算法,错误率再降50%。 |


 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号